Libro III, Título X Tablas de Mortalidad, Anexos
Anexo Nº 6 Nota técnica construcción tablas RV - 2009
Materias asociadas: Tablas de Mortalidad
I. Introducción
Con fecha 21 de febrero de 2004, se publicó la Ley N°19.934 que entre otras modificaciones al D.L. N° 3.500 de 1980 y al D.F.L. N° 251, de 1931, estableció que las tablas de mortalidad para efectos del cálculo de las reservas técnicas de los seguros de Renta Vitalicia, para el cálculo del Capital Necesario de las pensiones de Retiro Programado y de los Aportes Adicionales cubiertos por el seguro de invalidez y sobrevivencia, serán fijadas conjuntamente por las Superintendencias de Valores y Seguros y de Administradoras de Fondos de Pensiones.
Por otra parte, ambas Superintendencias establecieron las Tablas de Mortalidad RV 2004 H (hombres) y RV 2004 F (mujeres), las cuales rigen por un período máximo de cinco años a contar del 1° de febrero de 2008, según lo establecido en la correpondiente normativa.
En virtud de lo anterior, ambas Superintendencias han desarrollado dos nuevas tablas de mortalidad, para Rentistas RV-2009 H (hombres) y RV-2009 M (mujeres).
El proceso de construcción de las tablas se dividió en 4 etapas:
a) Obtención y depuración de datos.
b) Cálculo de expuestos y determinación tasas brutas de mortalidad.
c) Ajuste de tasas brutas de mortalidad y Aplicación de test estadísticos.
d) Cálculo de los factores de mejoramiento y márgenes de seguridad.
II. Obtención y depuración de base de datos
La base de datos utilizada para la construcción de la tabla se obtuvo de tres fuentes de información que involucran al sistema previsional chileno:
- Base de pólizas de Renta Vitalicia SVS.
- Base de pensionados del Sistema D.L. Nº 3.500 Superintendencia de Pensiones.
- Base de pensionados Sistema IPS (ex cajas de previsión)
Base de pólizas de Renta Vitalicia SVS
a) Conformación de la Base de Datos
Se utilizan los datos que trimestralmente envían las compañías de seguros, y reaseguros, correspondientes al Stock de pólizas y siniestros sea que se encuentren vigentes o hayan dejado de estarlo, conforme a lo establecido en la Letra A del Título II del Libro II y en la Letra D del Título I del Libro IV.
Los datos recibidos incluyen antecedentes de la póliza de renta vitalicia, o del siniestro antes mencionado, de los afiliados causantes de dichas pólizas.
b) Pólizas incluidas
Se utilizó el stock de datos al 31 de diciembre de 2008. Se incluyeron todas las pólizas de RV inmediata y RV diferida, en estas últimas tanto que se haya iniciado el pago de la renta vitalicia, como aquellas en que aún no comienzan a devengarse las rentas. Se incluyeron solo las pólizas donde el afiliado estaba vivo a partir del 1º de enero del 2000. En total se incluyeron 317.417 pólizas.
c) Depuración base de datos de personas duplicadas
Los registros duplicados se generan debido a la posibilidad que un causante de pensión tenga más de una póliza de renta vitalicia. En estos casos, se establece una regla general donde se mantienen los datos de la póliza más antigua.
d) Verificación de fechas de nacimiento y muerte
Con el objeto de tener una mayor certeza en los datos a utilizar en la construcción de las tablas de mortalidad, los datos fueron enviados al registro civil para verificar fechas de nacimiento, fallecimiento y sexo de las personas que constituyen esta base.
Base de pensionados del Sistema D.L. Nº 3.500 Superintendencia de Pensiones
a) Conformación de la Base de Datos
Se utilizó la información proporcionada mensualmente por las Administradoras de Fondos de Pensión, de Afiliados y Pensionados, conforme a lo establecido en el Título XI del Libro V.
Se consideró la información de afiliados hombres y mujeres pensionados con fecha de solicitud de pensión menor a 31/12/2008.
b) Depuración y Validación de los datos
Se efectuaron validaciones de consistencia de información entre las distintas tablas y/o archivos de la base de datos de Afiliados del Título XI del Libro V. Además se realizaron verificaciones de: formatos, contenidos, omisiones, repetidos, inconsistencias, etc.
De manera similar se verificaron datos particulares como montos de pensión y modalidad de pensión, contrastándose con la Base de datos Scomp y con la información entregada por la Superintendencia de Valores y Seguros.
c) Requerimientos de información a las Administradoras de fondos de pensión
Producto de lo anteriormente descrito fue preciso solicitar a las Administradoras aclaraciones, correcciones y datos de aquellos campos que no fue posible determinar en las fuentes de información utilizadas, que permitieran consolidar la información en la base de datos resultado.
d) Verificación de datos en el Registro Civil
Con el objeto de validar la información a utilizar, los datos fueron enviados al registro civil para verificar fechas de nacimiento, fallecimiento y sexo de las personas que constituyen esta base. La base de datos enviada a verificación consistió en alrededor de 180.000 registros correspondientes a Afiliados pensionados tanto vivos como fallecidos en retiro programado. Lo anterior, significa la totalidad de los Retiros Programados con excepción de aquellos pensionados que se encontraban en régimen de pago a Septiembre de 2008.
Base de pensionados Sistema IPS
a) Conformación de la Base de Datos
Se utilizó la base de datos proporcionada por el IPS conformada por todos los pensionados vivos y muertos al 31/12/2008. La base esta constituida por 520.099 datos de pensionados hombres y mujeres.
b) Depuración base de datos de personas duplicadas
La depuración de la base de datos consistió en dejar una sola vez cada afiliado causante.
Los registros duplicados se generan por la posibilidad que un causante de pensión sea pensionado de más de una caja.
c) Verificación de fechas de nacimiento y muerte
Con el objeto de tener una mayor certeza en los datos a utilizar en la construcción de las tablas de mortalidad, se envió la base de datos donde su resultado ha sido satisfactorio, y esto demuestra que efectivamente el INP realiza chequeos constantes con el Registro Civil de la misma.
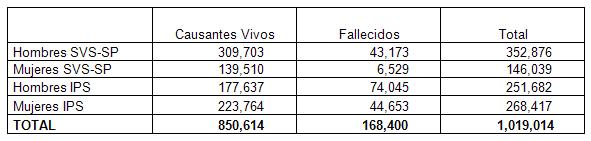
Base de Datos RV-2009 (fusión base de datos SVS-SP-IPS)
a) Conformación de la Base de Datos
Se fusionaron las bases de datos provenientes de la SVS, SP e IPS (antes mencionadas) en una sola, la cual es representativa de la mortalidad del rentista chileno.
Para esto se utilizó el monto de pensión como un filtro para discriminar los datos del sistema de reparto como de AFP.
b) Filtro de Pensión
Respecto de los datos provenientes del IPS se consideraron solamente aquellas personas con pensiones igual o mayor a la pensión mínima vigente al 31 de diciembre del 2008 para todos los expuestos vivos, mientras que para los fallecidos se considero la pensión mínima vigente a la fecha de fallecimiento. Lo anterior por cuanto dicha pensión corresponde al mínimo para las pensiones contributivas que se otorgan en virtud de la legislación correspondiente a la ex Cajas de Previsión.
Respecto de los pensionados del D.L. Nº 3.500 solo se consideraron se pensiones iguales o mayores a la pensión básica solidaria vigente al 1° de julio de 2009 (alrededor de 3,6UF). Lo anterior por cuanto a contar de dicha fecha, por aplicación de la Ley Nº 20.255, la pensión básica solidaria de vejez corresponde al mínimo exigido para contratar renta vitalicia.
c) Depuración base de datos de personas duplicadas
Debido a que una persona se puede traspasar de retiro programado a renta vitalicia, o afiliarse al Sistema de Pensiones regulado por D.L. Nº 3.500 despues de haber obtenido pensión en el sistema de reparto, se depuró completamente la base de repetidos teniendo en cuenta la variable RUT.
La base de datos quedo compuesta de la siguiente manera:
III. Metodología de Cálculo de Tasas Brutas y Expuestos
a) Nomenclatura y definiciones
En este informe se utiliza la notación actuarial generalmente aceptada.

Cálculo de las tasas brutas de mortalidad
El cálculo se efectúa de la siguiente manera:
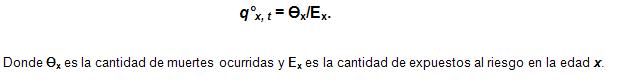
Cálculo de Expuestos al Riesgo
Primero es necesario calcular la edad asegurada "IA":
IA = Fecha exacta bautizo de la póliza - fecha exacta de nacimiento.
La fecha exacta se expresa en números decimales, para posteriormente aproximarla al número entero más cercano (edad actuarial).
Luego se recalcula la fecha de nacimiento (VYB) teniendo en cuenta la nueva edad a la toma del seguro.
VYB = CYI - IA
Donde CYI es el año calendario en que se bautizó la póliza (sin mes ni días).
Una vez obtenidos los valores de IA y VYB se puede calcular el siguiente vector:
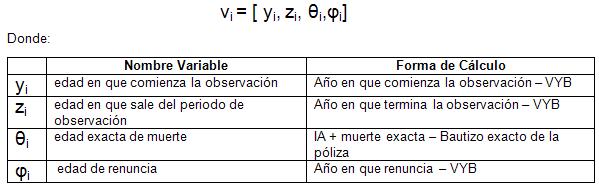
Una vez tenido esos datos se pueden calcular los expuestos y fallecimientos por año.
El cálculo se realiza de la siguiente forma:
Expuestos a la edad x = A la suma de todos los individuos que cumplan con estos requisitos:
Fallecimientos a la edad x = el subconjunto de expuestos a la edad x que cumplen con
b) Criterios para el cálculo de expuestos:
Para este cálculo se consideró un período de seis años, con cortes entre el 2002 y el 2007 inclusive, tanto para la información del sistema de capitalización individual como, para el sistema de reparto, IPS.
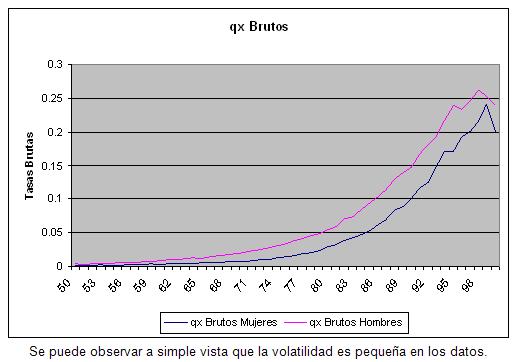
Los datos del INP no tienen relevancia en los primeros años, debido a que se trata de un universo de mayor edad que la del Sistema. Los datos del INP recién a partir de la edad 80 comienzan a influir para la construcción de las edades extremas.
En el gráfico podemos ver estas comparaciones:
IV. Técnica de ajuste
a) Método de Ajuste Whittaker Henderson Tipo B
El método de ajuste de Whittaker consiste en una combinación de regresión lineal y el método Bayesiano de ajuste.
Podemos definir la fórmula de Whittaker de la siguiente manera:
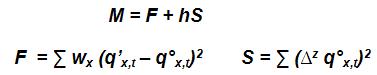
Donde F (fit) es la medida de ajuste mientras que S (smooth) es una medida de suavidad de la curva. Mientras que el parámetro h le da más o menos intensidad a la suavidad de la curva.
Descripción de F:
Esta es la parte asociada a la minimización de los residuos cuadrados,
En esta formula el tamaño de la muestra esta ponderando los residuos
Es decir que mientras F tiende a cero el ajuste es mejor.
En los casos en que los residuos tienen una muestra grande (wx) deben ser más pequeños para mantener F lo más cerca de cero.
El ponderador wx toma en cuenta la varianza de una distribución normal de la variable aleatoria Ux. Donde Ux es una variable aleatoria binomial pero puede ser aproximada por una variable aleatoria normal siempre que el numero de observaciones nx se lo suficientemente grande.
Sabemos que la varianza es inversamente proporcional al número de observaciones. A mayores observaciones la varianza disminuye.
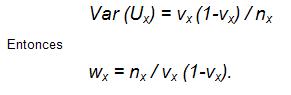
Aquí se ve claramente que el ponderador da mas importancia al qx bruto cuya varianza es menor (el ponderador va ser mas grande).
Descripción de S:
Ahora es necesario definir la medida para definir la suavidad de la curva. Generalmente se utilizan las diferencias finitas de diferente orden sobre los valores de qx brutos para cuantificar una medida de suavidad.
Esto se puede representar de la siguiente manera:
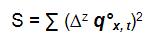
"S" se obtiene de la suma cuadrada de las diferencias finitas. Si por ejemplo z = 4 estamos considerando que la secuencia qx se asemeja a un polinomio de grado 3. Debemos recordar que las diferencias finitas se asemejan a una derivada y por lo tanto el orden de diferencia condiciona el grado del polinomio.
Para encontrar los valores de qx ajustados es necesario minimizar M, que es una función con n incógnitas de los valores qx. Entonces los qx que minimizan M corresponden a la solución para las n ecuaciones como resultado de la derivada parcial de M con respecto a qx.
Es posible hallar este resultado representando el problema en forma matricial.
b) Coeficientes utilizados para la construcción de las tablas:

La diferencia finita, es de grado tres, la cual se asemeja a un polinomio de grado dos, y fue la función que me mejor se adoptó a los datos analizados.
Por otro lado, el coeficiente h, es obtiene de manera iterativa, hasta que se obtenga una función creciente constante, de manera similar a una función exponencial.
V. Test estadísticos
El problema con el ajuste de las tasas brutas de mortalidad es ver si estos realmente representan la población estudiada. La principal forma de verificar si esto es así, es a través de test estadísticos los cuales nos indican que tan fidedigno es el ajuste en comparación con los datos observados. Bajo este escenario podemos describir brevemente los siguientes test:
a) El test de Chi Cuadrado
Es un Test completo que solo se utiliza como referencia para ver si las tasas brutas de mortalidad representan a dicha población. Mide las desviaciones estándar de la estimación respecto de las tasas brutas de mortalidad. Una de las grandes limitaciones de este Test es que puede haber grandes desviaciones en ciertas edades, mientras que para otras edades son pequeñas por lo que el resultado final es aceptable según el Test. Deseablemente estas desviaciones deben ser lo mas constante para obtener un buen resultado. En caso que no pase dicho test, no significa que el ajuste no sea el adecuado, siempre y cuando pase satisfactoriamente todo los demás tests.
b) Test de Desviaciones Estandarizadas
Este test estandariza las desviaciones estándar para que sean comparables entre si y fija un nivel de confianza para que estas desviaciones no sean mayor a un cierto numero. Es decir si las desviaciones no son homogéneas y con un grado menor al deseado es muy probablemente que no pase el test.
c) Test de Desviaciones Absolutas
Este test refleja que las desviaciones absolutas no sean mayores a un cierto número (generalmente se utiliza que éstas no sean mayores a una unidad de la variable normal, o sea de alrededor de 2/3.)
d) Test de Desviaciones Acumuladas
Los fallecimientos en las distintas edades deben ser independientes, y se deben representar en una variable aleatoria normal. Por esta razón las desviaciones Standard deben ser relativamente homogéneas durante todos los tramos. La hipótesis nula a testear es que las desviaciones acumuladas no deben ser mayores al doble de la raíz cuadrada de la varianza de la distribución.
e) Test de Signos
Si tomamos en consideración que la hipótesis nula es que las desviaciones observadas de las muertes respecto de las muertes esperadas son una variable normal independiente, lo mismo debe ocurrir con los signos encontrándose un número similar de éstos, tanto positivo como negativo.
f) Test de Stevens
Es similar al test de signos. Estos signos pueden ser todos positivos al principio y luego todos negativos al final del ajuste, por lo que el test de Stevens observa subgrupos de signos a través de la tabla y computa el signo de cada subgrupo. Luego en estos subgrupos deben estar distribuidos de manera similar tanto los signos positivos como negativos.
g) Test de Cambio de Signo
La probabilidad de cada signo es independiente y está representada en una variable normal, por lo que se puede aplicar una variable binomial donde el signo positivo o negativo tiene la misma probabilidad, ½ .Con esto se quiere ver que los cambios de signo sean homogéneos y no presenten anomalías.
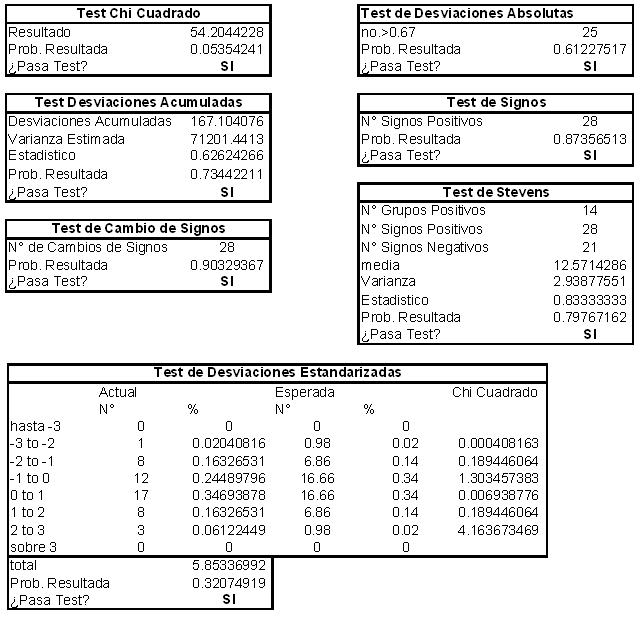
Resultado de los Test:
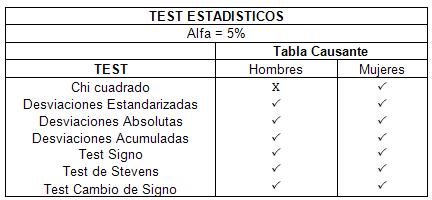
Como podemos ver, la tabla de hombres pasa todos los test menos el de Chi cuadrado. Mientras que en el ajuste de las mujeres pasa los 7 tests.
En el apéndice de la nota técnica se detalla cada test.
VI. Construcción de Tablas
1. Construcción de colas
Los datos son representativos hasta la edad de 99 años, por lo que se tiene una buena base para poder extrapolar dos datos faltantes de la tabla, por lo cual no es necesario utilizar varios modelos de mortalidad para estimar éstas. Simplemente, se continúa por 10 años más con la tendencia exponencial de la curva del ajuste (Whitakker Henderson), lo cual resulta en una extrapolación de las tasas ajustadas para las edades sobre 100 años. Para realizar esto, simplemente se pone en el ajuste un valor de Wx = 0 para las edades superiores a 99 años.
2. Construcción de edades tempranas
Al no tener datos en las edades tempranas, simplemente se consideró el qx de la RV 04 y se aplicó el factor de mejoramiento vigente para que los datos sean representativos al año 2009. Estos datos, debieron ser empalmados con los datos del ajuste, por lo que se suavizó dicho empalme con tasas promedios de ambos. Es importante recordar, que los datos mayores a 50 años, son resultado 100% del ajuste de los datos.
VII. Factores de mejoramiento y márgenes de seguridad
1. Factores de mejoramiento
Se optó por mantener los factores de mejoramiento de la RV-04, los cuales fueron construidos en base al censo poblacional del año 2002, realizado por el INE (Instituto Nacional de Estadística). Estos factores son los que se encuentran implícitos en las proyecciones de mortalidad del CELADE.
Estas proyecciones fueron implementadas en la tabla RV-09 de acuerdo a la siguiente fórmula:

2. Márgenes de seguridad
Se mantuvieron los criterios de márgenes de seguridad considerados en las tablas RV-2004. Esto es, no se consideraron márgenes de seguridad en el caso de mujeres y para hombres se incorporaron márgenes de seguridad desarrollados de acuerdo a la siguiente fórmula:

Se utilizó como máximo un margen del 3%.
APÉNDICE
Detalle Test Estadísticos
Hombres:
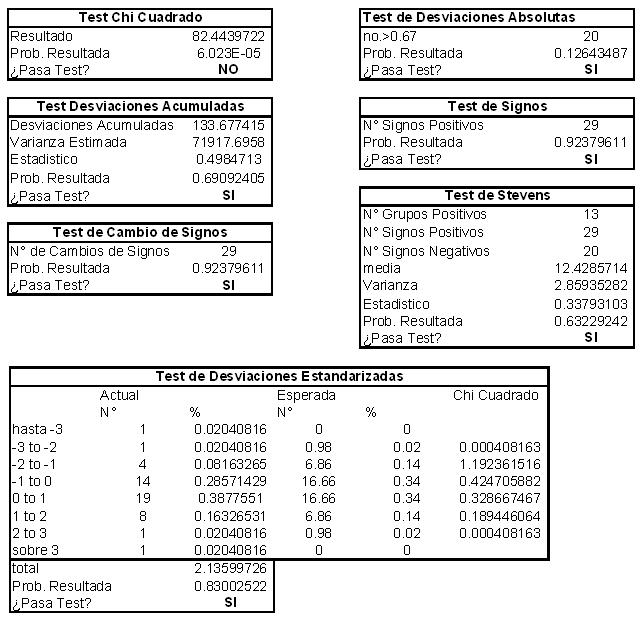
Mujeres: